A multi-national clothing maker has over a thousand retail stores, sells certain lines through department and discount stores, and has an online presence. Currently, these three channels all act independently from a technical standpoint. They have different management, point-of-sale systems, and accounting departments. There is no system that merges all of these data sets together to allow the CEO to have insight across the business. The CEO wants to have a company-wide picture of its channels and be enabled to do ad hoc analytics when required. Example analytics that the company wants are:
What trends exist across channels?
What geographic regions do better across channels?
How effective are their advertisements and coupons?
What trends exist across each clothing line?
What external forces may have an impact its sales, for example unemployment rate, or the weather?
How does store attribute effect sales, for example tenure of employees/management, strip mall versus enclosed mall, location of merchandise in the store, promotion, endcaps, sales circulars, in-store displays, etc.?
An enterprise data warehouse is a terrific way to solve this problem. The data warehouse needs to collect data from each of the three channels’ various systems and from public records for weather and economic data. Each data source sends data on a daily basis for consumption by the data warehouse. Because each data source may be structured differently, an extract, transform, and load (ETL) process is performed to reformat the data into a common structure. Then, analytics can be performed across data from all sources simultaneously. To do this, we use the following data flow architecture:
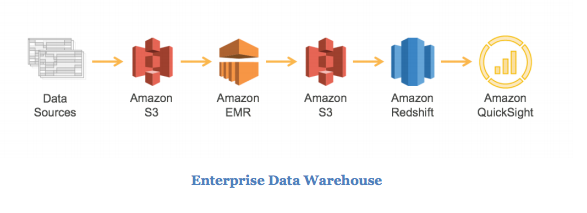
1. The first step in this process is getting the data from the many different sources onto Amazon S3. Amazon S3 was chosen because it’s a highly durable, inexpensive, and scalable storage platform that can be written to in parallel from many different sources at a very low cost.
2. Amazon EMR is used to transform and cleanse the data from the source format into the destination and a format. Amazon EMR has built-in integration with Amazon S3 to allow parallel threads of throughput from each node in your cluster to and from Amazon S3. Each source may have a different transformation process on Amazon EMR, but with AWS’s pay-as-you-go model, you can create a separate Amazon EMR cluster for each transformation and tune it to be the exact right power to complete all data transformation jobs for the lowest possible price without contending with the resources of the other jobs.
3. Each transformation job then puts the formatted and cleaned data onto Amazon S3. Amazon S3 is used here again because Amazon Redshift can consume this data on multiple threads in parallel from each node. This location on Amazon S3 also serves as a historical record and is the formatted source of truth between systems. Data on Amazon S3 can be consumed by other tools for analytics if additional requirements are introduced over time.
4. Amazon Redshift loads, sorts, distributes, and compresses the data into its tables so that analytical queries can execute efficiently and in parallel. Amazon Redshift is built for data warehouse workloads and can easily be grown by adding another node as the data size increases over time and the business expands.
5. For visualizing the analytics, Amazon QuickSight can be used, or one of the many partner visualization platforms via the OBDC/JDBC connection to Amazon Redshift. This is where the reports and graphs can be viewed by the CEO and her staff. This data can now be used by the executives for making better decisions about company resources, which can ultimately increase earnings and value for shareholders.
This architecture is very flexible and can easily be expanded if the business expands, more data sources are imported, new channels are opened, or a mobile application is launched with customer-specific data. At any time, additional tools can be integrated and the warehouse scaled in a few clicks by increasing the number of nodes in the Amazon Redshift cluster.
Source: Big Data Analytics options on AWS
